The following datasets developed by AI Research are available for public use for non-commercial purposes subject to the terms of each dataset’s original license.
Contact us to request access to a dataset.
DocLLM: Instruction tuning dataset
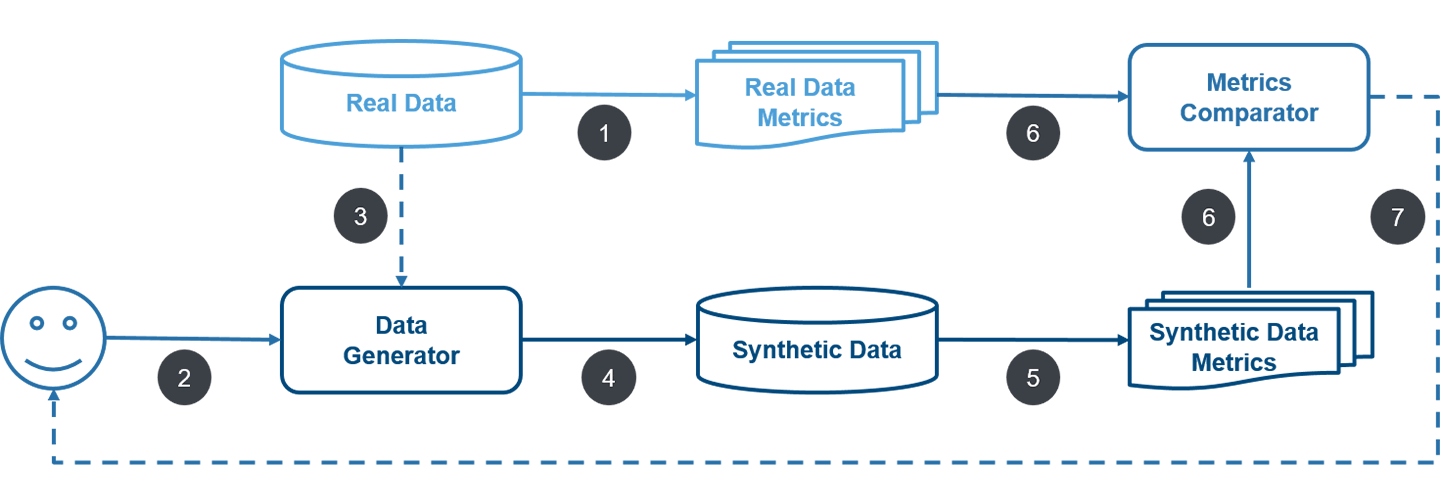
Motivation: Visually-rich Document Understanding (VrDU) models require deeply annotated datasets for training and validation. A diverse collection of such datasets exists for tasks such as Key Information Extraction, Document Classification, and Question Answering. With the recent popularity of Large Multimodal Language Models, researchers have shifted to using instruction tuning datasets that are more suitable for Generative Models. This has led to a bottleneck, as new datasets need to be created, or prior datasets need to be converted into a new format that is suitable for instruction tuning.
Outcome: To address this issue, AI Research has converted 16 previously published collections into instruction tuning datasets, covering the four tasks of Key Information Extraction, Document Classification, Visual Question Answering, and Natural Language Inference/Tabular Reasoning. The dataset enables researchers to seamlessly train and test their models against a wide variety of tasks and collections. It also creates a unified benchmark against which future models can be evaluated.
Citation:
Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. 2024. DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding (ACL’24), August 11-16, 2024, Bangkok, Thailand, 9 pages.
Datasets cont’d
This collection includes a set of 16 previously released VrDU datasets, and is meant to be used for research purposes only. Users are subject to the terms of each dataset’s original license.
REFinD: Relation extraction financial dataset
Motivation: Relation extraction (RE) from text is a core problem in Natural Language Processing (NLP).
Datasets for Relation Extraction (RE) are created to aid downstream tasks such as building knowledge graphs, information retrieval, semantic search, question/answering and textual entailment. However, most available large-scale RE datasets are compiled using general knowledge sources such as Wikipedia, web texts and news. These datasets often fail to capture domain-specific challenges. Therefore, various state-of-the-art models that perform competitively on such datasets fail to perform well in the financial domain.
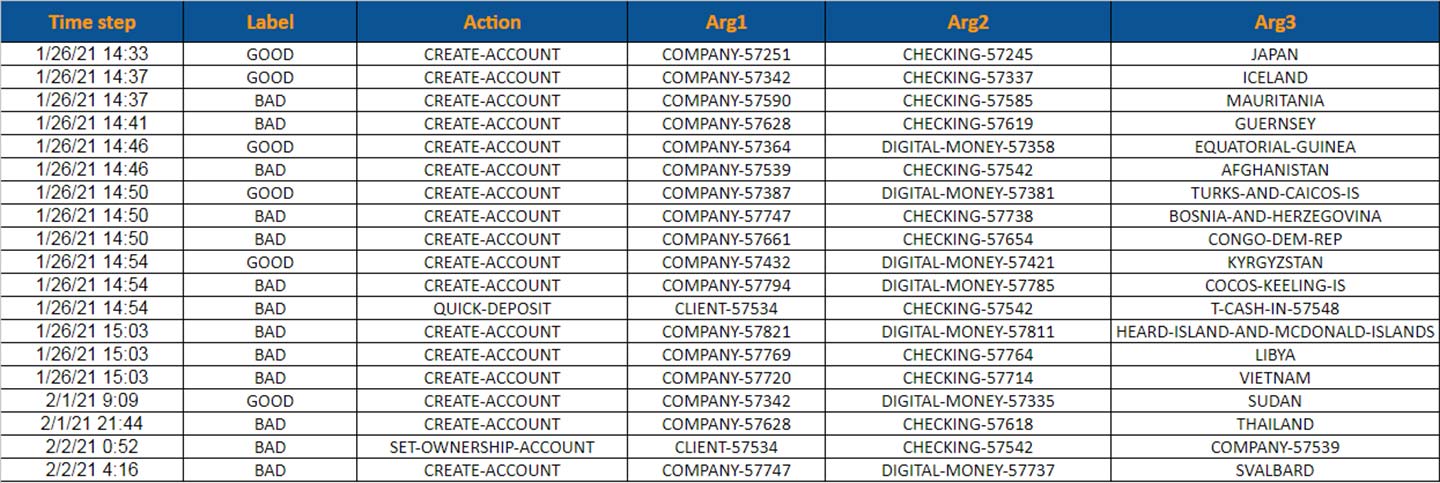
Outcome: To address this limitation, AIR has created REFinD, Relation Extraction Financial Dataset. It is the largest-scale annotated dataset of relations, with ∼29K instances and 22 relations among 8 types of entity pairs, generated entirely over financial documents. It is the first RE dataset to use Security and Exchange (SEC) filings a rich and complex data source. The team introduced diversity in the dataset by including all context surrounding the entities, capturing longer contexts than seen in financial texts.
Citation:
Simerjot Kaur, Charese Smiley, Akshat Gupta, Joy Sain, Dongsheng Wang, Suchetha Siddagangappa, Toyin Aguda, and Sameena Shah. 2023. REFinD: Relation Extraction Financial Dataset. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’23), July 23–27, 2023, Taipei, Taiwan, 9 pages. https://doi.org/10.1145/3539618.3591911
This dataset is licensed under the Creative Commons Attribution-Noncommercial 4.0 International License. Therefore, the dataset provided may only be used for non-commercial purposes and may not be used for any commercial use.
BizGraphQA: A Dataset for Image-based Inference over Graph-structured Diagrams from Business Domains
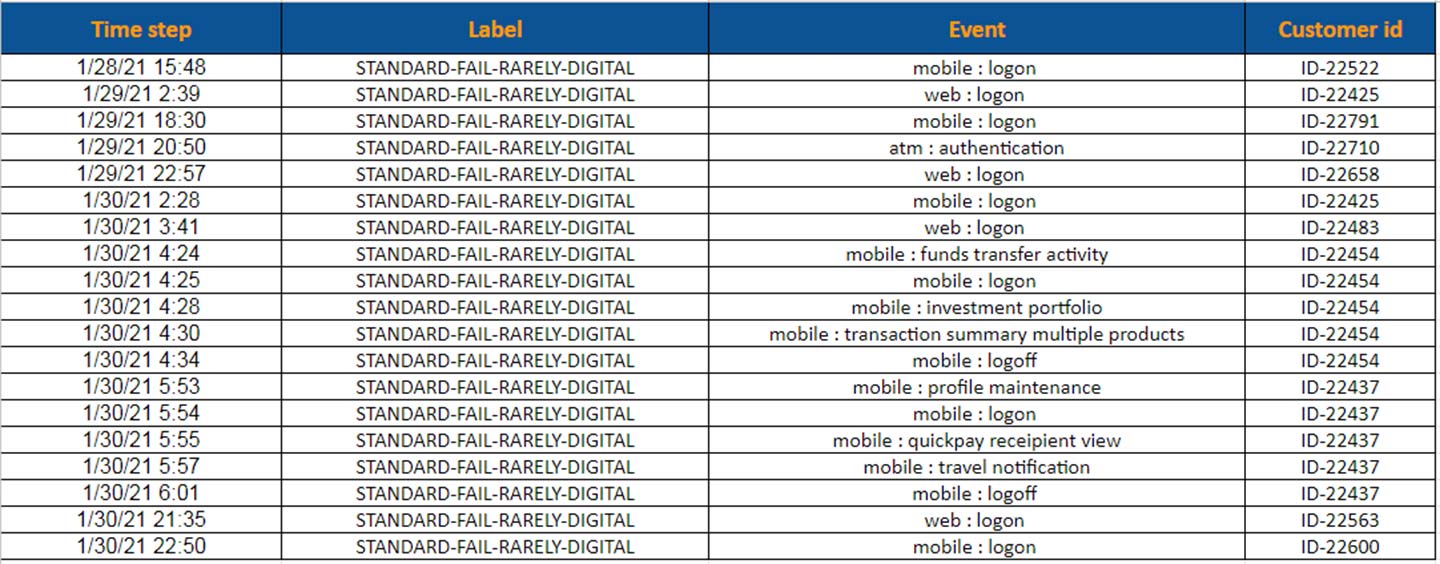
Motivation: Graph-structured diagrams, such as enterprise ownership charts or management hierarchies, are a challenging medium for deep learning models as they not only require the capacity to model language and spatial relations but also the topology of links between entities and the varying semantics of what those links represent. Devising Question Answering models that automatically process and understand such diagrams have vast applications to many enterprise domains, and can move the state-of-the-art on multimodal document understanding to a new frontier.
Curating real-world datasets to train these models can be difficult, due to scarcity and confidentiality of the documents where such diagrams are included. Recently released synthetic datasets are often prone to repetitive structures that can be memorized or tackled using heuristics.
Outcome: In this paper, we present a collection of 10,000 synthetic graphs that faithfully reflect properties of real graphs in four business domains, and are realistically rendered within a PDF document with varying styles and layouts. In addition, we have generated over 130,000 question instances that target complex graphical relationships specific to each domain. We hope this challenge will encourage the development of models capable of robust reasoning about graph structured images, which are ubiquitous in numerous sectors in business and across scientific disciplines.
Citation:
Petr Babkin, William Watson, Zhiqiang Ma, Lucas Cecchi, Natraj Raman, Armineh Nourbakhsh, and Sameena Shah. 2023. BizGraphQA: A Dataset for Image-based Inference over Graph-structured Diagrams from Business Domains. In Proceedings of the 46th International ACM SIGIR Conference on
Research and Development in Information Retrieval (SIGIR ’23), July 23–27, 2023, Taipei, Taiwan. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3539618.3591875 dataset provided may only be used for non-commercial purposes and may not be used for any commercial use.