Unlike most resources, data does not diminish in value as it is used. The same data can be used in many places, and the more combinations of data an organization creates—such as between reference data and data from business processes across the enterprise—the more value it can extract via enterprise-wide visibility, real-time analytics, and more accurate AI and ML predictions. Organizations that are good at sharing data internally as legally permissible will realize more value from their data resources than organizations that aren’t.
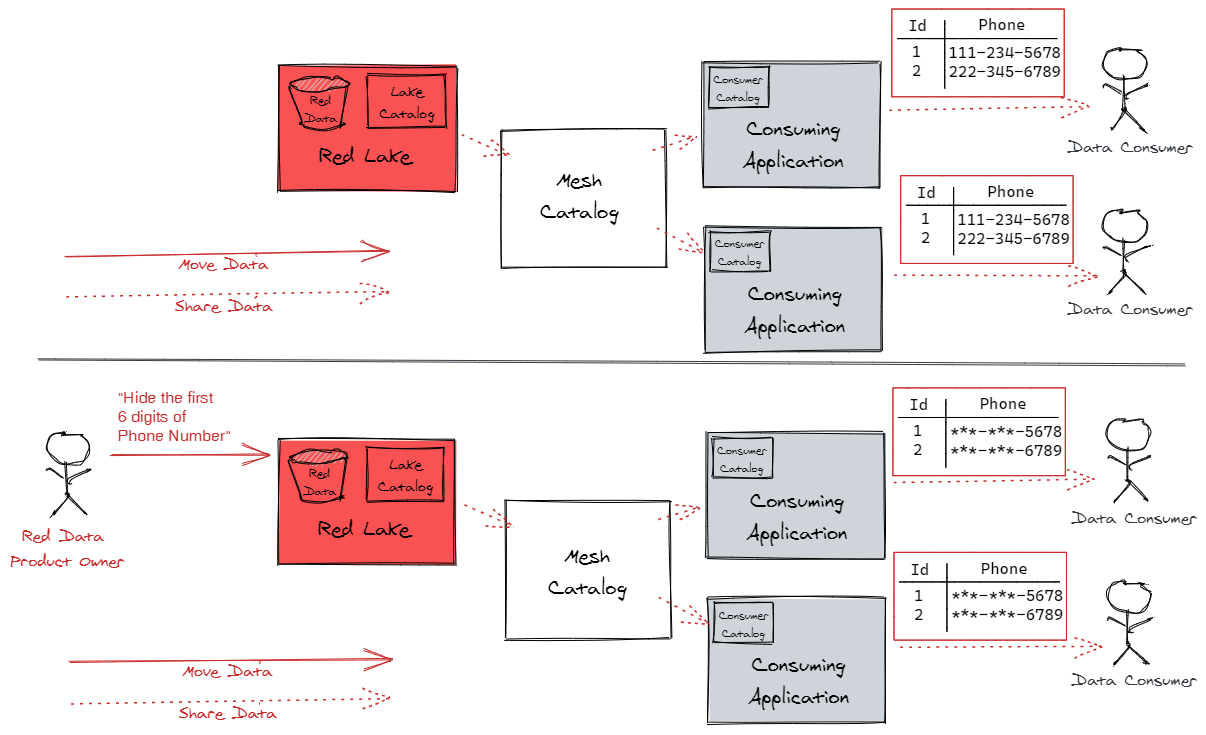
But like any resource, data risks must be managed, particularly in regulated industries. Controls help to mitigate such risks, so organizations that have strong controls around their data are exposed to less risk than those that don’t.
This presents a paradox: data that is permitted to be freely shareable across the enterprise has the potential to add tremendous value for stakeholders, but the more freely shareable the data is, the greater the possible risk to the organization. To unlock the value of our data, we must solve this paradox. We must make data easy to share across the organization, while maintaining appropriate control over it.
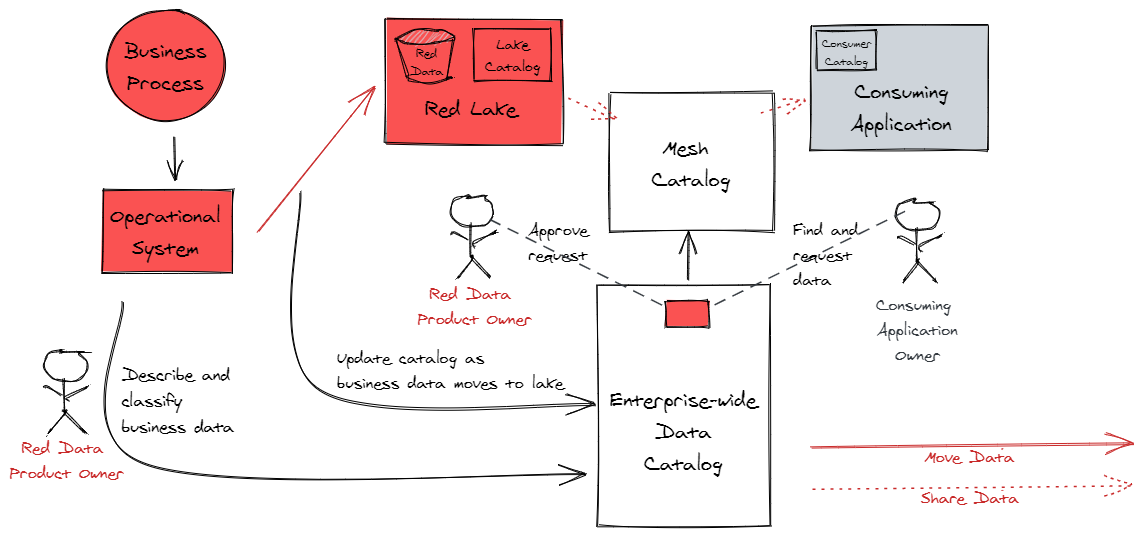
JPMorganChase is taking a two-pronged approach to addressing this paradox. Firstly, by defining ‘Data Products,’ which are curated by people who understand the data and its management requirements, permissible uses and limitations. And secondly, by implementing a ‘Data Mesh’ architecture, which allows us to align our data technology to those data products.
This combined approach:
- Empowers data product owners to make management and use decisions for their data
- Enforces those decisions by sharing data, rather than copying it
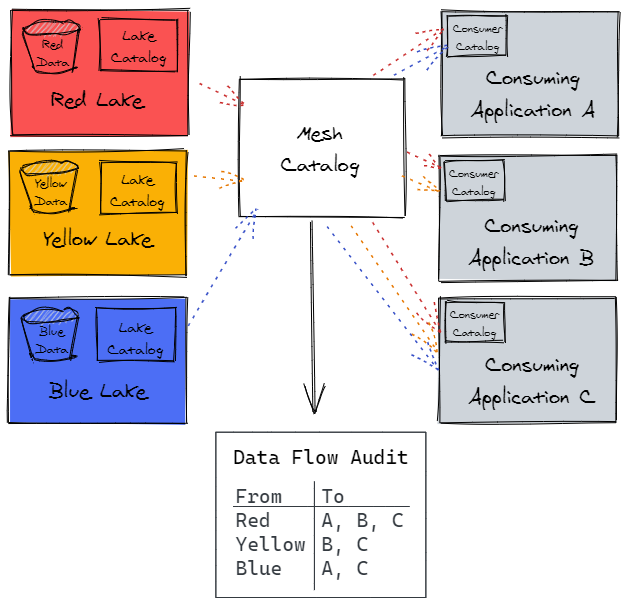
- Provides clear visibility of where data is being shared across the enterprise
Let’s first look at what the Data Mesh is, and then at how the Data Mesh architecture supports our Data Product strategy, and how both enable our businesses.
Aligning our Data Architecture to our Data Product Strategy
JPMorganChase is comprised of multiple lines of business (LoBs) and corporate functions (CFs) that span the organization. To enable data consumers across JPMorganChase’s LoBs and CFs to more easily find and obtain the data they need, while providing the necessary control around the use of that data, we are adopting a Data Product strategy.
Data products are groups of related data from the systems that support our business operations. They are broad but cohesive collections of related data. We store the data for each data product in its own product-specific data lake. We provide physical separation between each data product lake. Each lake has its own cloud-based storage layer, and we catalog and schematize the data in each lake using cloud services. One can use cloud based storage and data integration services such as AWS S3 and AWS Glue to provide those storage and cataloguing capabilities.
The services that consume data are hosted in consumer application domains. These consumer applications are physically separated both from each other and from the data lakes. When a data consumer needs data from one or more of the data lakes, we use cloud services to make the lake data visible to the data consumers, and provide other cloud services to query the data directly from the lakes. One could use cloud based lake formation and data cataloging services such as AWS LakeFormation and Glue Catalog to make data visible, and interactive data query services such as AWS Athena to query the data.
The data product-specific lakes that hold data, and the application domains that consume lake data, are interconnected to form the data mesh.